
Data Collection for Humanoid Robots: Hardware, Software, and Emerging Technologies


Humanoid robots – general-purpose, bipedal machines designed to operate in human environments – rely on vast sensory and training data to function. Modern humanoids carry advanced sensor suites (cameras, LiDAR, microphones, IMUs, tactile arrays, etc.) that feed into AI models for perception and control[1][2]. These sensors produce multimodal streams (vision, depth, inertial, audio, touch, etc.) which are fused by computer vision and learning algorithms to build world models and plan actions. For example, Boston Dynamics notes robots “rely on a mix of … lidar, visual cameras, and other sensors feeding data to software systems”[1]. Data collection systems range from motion-capture teleoperation to egocentric wearable rigs[3][4]. In recent years, the field has seen rapid advances in deep learning (especially vision-language models), simulation-to-real transfer, and large-scale data collection, but also faces challenges in real-time processing, data scarcity, privacy, and lack of shared standards.
Sensor Hardware and Data Streams
Humanoid robots gather data via diverse sensors:
Vision sensors: High-resolution RGB cameras (standard, wide-angle/360°, stereo rigs) and depth sensors provide rich visual inputs. Stereo/3D cameras allow depth perception; thermal and infrared cameras reveal heat signatures; acoustic arrays (mic + camera) localize sound[5][6]. For example, Boston Dynamics’ Spot uses stereo and PTZ cameras for depth and detail, plus optional 360° and thermal cameras for context-rich mapping[7][8]. Vision data fuel object recognition, scene understanding, and SLAM (simultaneous localization and mapping).
Range and LIDAR: 3D LiDAR (light detection and ranging) is common for mapping and navigation[5]. Humanoids like Atlas and Tesla’s Optimus may use LiDAR or radar for obstacle detection beyond camera range. LiDAR can work in low-light or feature-sparse environments (e.g. recognizing container walls in darkness[9]). Some systems also incorporate mm-wave radar for contactless sensing (e.g. TI’s IWR6843 radar used in research prototypes).
Proprioceptive sensors: Internal sensors measure the robot’s own state. These include joint encoders (position/velocity), force/torque (F/T) sensors in limbs or feet, and inertial measurement units (IMUs). Proprioceptive data are essential for balance and control. For instance, humanoid state estimation frameworks fuse joint/IMU signals to compute center-of-mass, zero-moment-point, and foot forces[10][11]. Joint encoders and F/T sensors capture low-level robot responses to commands, which, when logged, help diagnose control issues[12].
Tactile and haptic sensors: Many humanoids have touch/pressure sensors on hands/feet. These capture contact forces (e.g. thumb pad pressure, foot sole feedback) important for grasping and stable locomotion. Emerging research also uses arrays of capacitive or vision-based touch on fingers. In human-instrumented datasets (e.g. kitchen manipulation), tactile gloves and force plates record contact data for learning dexterous manipulation.
Audio and language: Microphones capture speech and environmental sounds. Natural Language Processing (NLP) modules translate voice commands into actions. Some humanoids integrate speech recognition (using transformer-based models) and even neural language models (LLMs) to parse instructions[13]. Speech data may be collected and labeled for training conversational agents and intent classifiers.
Egocentric wearables: For imitation learning, researchers use egocentric rigs on humans to collect data. For example, Project Aria smart glasses (Meta) capture first-person video and gaze, synchronized with wearable IMUs or hand cameras[4]. The EgoMimic framework co-trains humanoid policies on these human demonstrations, showing that 1 hour of extra human video data can outperform 1 hour of robot data for learning kitchen tasks[4].
In practice, a humanoid’s data collection pipeline may combine on-board and off-board streams. Agility Robotics reports that their Digit robot logs (1) raw environmental data (camera/LiDAR frames, touch, IMU) and (2) robot-response data (control commands, joint torques, foot contact) at high rates[2][12]. These are supplemented by (3) high-level telemetry about tasks, health, and decisions[14]. Together, these streams enable building world models and debugging failures. However, raw vision/LIDAR recordings can inadvertently capture personal imagery, raising privacy issues[15]; companies must carefully anonymize or delete sensitive data.
The fusion of these modalities is achieved through software frameworks (e.g. ROS/ROS2 middleware, MoveIt, OpenCV) and deep learning models. Modern humanoids use CNNs and transformer-based models for image processing, speech-to-text engines for audio, and multimodal architectures (e.g. CLIP-like models) to link visual and language inputs. Data from different sensors are time-synchronized (often via timestamps or hardware sync) so that, for instance, an RGB frame, a LiDAR scan, and corresponding robot proprioception align in time for perception and control algorithms[12][16].
Modern Data Collection Methodologies
In the past five years, several new methods have accelerated humanoid data gathering:
Teleoperation with motion capture: Human operators wear mocap suits (or VR rigs) to demonstrate tasks. Tesla’s Optimus team initially used motion-capture suits and VR controllers to record human motions for training the robot[17]. Similarly, Boston Dynamics teleoperates Atlas: operators perform tasks in mocap suits, and those joint trajectories train the robot[18]. Agility’s Digit also uses teleop: they employ tablet interfaces and motion rigs for human demonstration. These approaches yield synchronized state-action pairs (human states to robot states) for imitation learning. For instance, Tesla hires “Data Collection Operators” to walk preset routes in mocap gear, teleoperating Optimus and generating refinement data[3]. However, such methods are labor-intensive and hard to scale beyond the lab.
Video-based learning: Inspired by large vision models, companies now try to train robots from raw video. In 2025, Tesla switched Optimus to primarily use first-person task videos instead of elaborate teleop rigs[17]. Elon Musk even suggested Optimus should learn by watching YouTube. The advantage is scale: video data (from factories, workers, or web) is plentiful. The challenge is that “translating video data to the real world” for robots is hard without direct state measurement[18]. Still, this “learning from videos” approach is growing, and research (e.g. EgoMimic) shows promise in aligning video with robot embodiments[4].
Crowdsourced data platforms: Startups are emerging to systematize data collection. Sensei Robotics (YC Summer 2024) builds a “Scale AI for robotics” platform: they provide inexpensive wearable exoskeletons and a network of human operators (“Senseis”) to record diverse robot demonstrations across many locations[19][20]. Their analytics show human demonstrations can be gathered 2× faster and 10× cheaper than traditional lab teleop[19]. Sensei’s platform records video, angles, and inertial data from operators performing tasks, then packages it for client use.
Motion-capture studios and synthetic data: Other companies focus on large-scale motion capture. Korea’s Movin (Naver-backed) built an in-house mocap studio to record millions of human motions for training robots[21]. 3D animation firms like Rokoko have amassed huge motion libraries (1M+ clips) that can seed humanoid actions[22]. These datasets (sitting, walking, gesturing, dancing) can be adapted for robots using inverse kinematics. For example, Unitree Robotics released an open-source “dance” dataset for its H1/G1 robots, captured via LAFAN1 mocap[23]. By applying kinematic retargeting, Unitree’s robots can mimic human motions (even dancing) more naturally[23]. Such opensource motion datasets (shared via HuggingFace, Unity Asset Store, etc.) help researchers accelerate humanoid motion learning.
Simulation and digital twins: Robotics simulators (NVIDIA Isaac, Unity Robotics/ML-Agents, PyBullet, MuJoCo) are used to generate synthetic training data. Companies like Tesla and Boston Dynamics use simulation to validate controllers before real-world testing. Synthetic environments can produce annotated multimodal data (RGB-D, segmentation, physics) at scale. Recent trends include domain randomization to narrow the sim-to-real gap and training in photorealistic simulators (e.g. NVIDIA Omniverse). While synthetic data avoids privacy issues, achieving perfect realism remains a challenge, especially for hand-object contact and tactile signals.
Software and AI Integration
On the software side, major advances have shaped data use in humanoids:
Deep Learning and Vision Models: Convolutional Neural Networks (CNNs) and, more recently, Transformer-based vision-language models (VLMs) dominate perception. Modern state-of-the-art systems use pre-trained image encoders (ResNet, ViT) and multi-modal encoders (CLIP-like, BLIP) to process camera feeds. These models can identify objects and infer spatial relationships. Surveys highlight that VLMs now enable zero-shot understanding and instruction following in robotics[24][25]. For example, large pre-trained models can interpret commands like “pick up the red mug” by grounding words to vision.
Multimodal fusion: Contemporary systems fuse data from all sensors. The recent review by Han et al. (2025) notes that robot vision often requires combining RGB, depth, LiDAR, language, and other inputs to overcome occlusions and ambiguity[26][27]. Advanced fusion architectures (attention-based encoder-decoder models, graph networks) are used for tasks like semantic mapping, SLAM, and manipulation. Key challenges remain “efficiently integrating heterogeneous data” and doing so in real time[26][28]. Edge AI hardware (e.g. Nvidia Jetson, AWS Snowball Edge, Google Coral) is increasingly deployed onboard for live inference with low latency.
Language and Dialogue: NLP and dialogue systems enable intuitive robot control. Humanoids often incorporate speech recognition engines (sometimes connected to cloud-based LLMs) to parse high-level instructions. The 2025 kitchen dataset paper by Ren et al. argues that large language models have transformed HRI, allowing natural commands, but they typically rely on unimodal text; adding rich sensory data (audio, touch, EMG) can improve understanding[13][29]. Thus, modern humanoids may use multimodal transformer models that jointly consider vision and speech (e.g. Visual Dialog or Vision-Language models like LLaVA).
Real-time processing: Processing sensor data on the fly is critical. Boston Dynamics highlights that “multi-sensor vision systems” (LiDAR + cameras + thermal, etc.) are processed by AI models on-board to enable agile responses[8]. Low-latency pipelines (often using GPU/FPGA acceleration) ensure that feedback from cameras or contact sensors can adjust gait or grasping immediately. This requires optimized software stacks (e.g. real-time Linux, ROS2 DDS, GPU-accelerated libraries) and careful data compression.
Data annotation and labeling: Generating labeled training data is still largely manual or semi-automated. Projects may use simulation for auto-labels (depth maps, segmentation), but real-world data often require human annotation (bounding boxes, action labels). Startups like Sensei envision crowdsourcing this: human operators not only collect data but provide labels via a managed marketplace[20]. Some academic efforts (e.g. EgoMimic) align human video with robot kinematics in an unsupervised way, reducing labeling effort[4].
Challenges and Research Trends
Despite progress, several challenges persist:
Real-Time Data Capture: Humanoid robots produce high-bandwidth data (HD video, 3D point clouds, IMU at kHz). Streaming or storing all this in real time is difficult onboard. Wireless offloading (5G/6G) is limited by latency and power. As a result, many robots employ on-device preprocessing (e.g. region-of-interest cropping, event cameras) and selective logging. Managing synchronization across sensors is non-trivial, as misalignment can corrupt learning. Hanson et al. (2025) note real-time deployment as a key open problem[26].
Training Dataset Generation: Ken Goldberg (UC Berkeley/Ambi Robotics) highlights a massive “data gap” between data available for vision-language models and robotics models[30]. He estimates humanoids need on the order of 100,000× more data to approach LLM-scale capabilities. Generating large, diverse datasets is therefore a bottleneck. Traditional teleoperation yields only thousands of hours; Ambi Robotics amassed 200,000 hours of warehouse robot data for sorting tasks[30], but broader tasks require even more. Synthetic augmentation, self-supervised learning, and leveraging internet videos (as Tesla attempts) are active research trends to close this gap.
Edge Computing and Hardware Limitations: Humanoids have constraints on weight, size, and battery life, limiting compute power. Integrating AI accelerators (NVIDIA Orin, Intel Movidius, custom ASICs) is crucial but still energy-expensive. Balancing computation between onboard (for instant control) and cloud (for heavy training) is an open issue. Retraining large models on-device is currently impossible, so iterative data cycles (collect, send to cloud, update models, redeploy) dominate.
Privacy and Security: Humanoids operate in personal spaces. Their sensors can capture sensitive PII (faces, voices). Privacy regulations (GDPR, CCPA) and public concern require on-device anonymization (face blurring, encryption) or strict data policies. Agility Robotics explicitly notes the need to carefully “transmit and store” camera/LiDAR data to avoid leaks[15]. Moreover, stored datasets pose security risks (breaches could expose private video/audio). Standard practices (data minimization, secure enclaves) are still maturing in the robotics context.
Standardization and Data Sharing: Currently there is no universal standard for humanoid data formats or sharing. Unlike self-driving cars (KITTI, Waymo Open Dataset, etc.), there are few large public humanoid datasets. Recognizing this, China’s new Humanoid Robot Innovation Center (NLJIC) announced an initiative to create shared data ecosystems and industry standards[31][32]. They plan humanoid “training grounds” to collect high-quality data and even introduced technical levels (L1–L4) and intelligence levels (G1–G5) for humanoids, akin to driving automation tiers[32]. Internationally, groups are calling for open “robotic data commons” and unified formats (e.g. standardized ROSbag specifications, schema for multimodal logs). However, progress is nascent, and much data remains siloed within companies.
Notable Startups and Data-Tech Innovators
Table 1 summarizes key humanoid robot and data technology startups, focusing on those advancing data collection or AI integration:
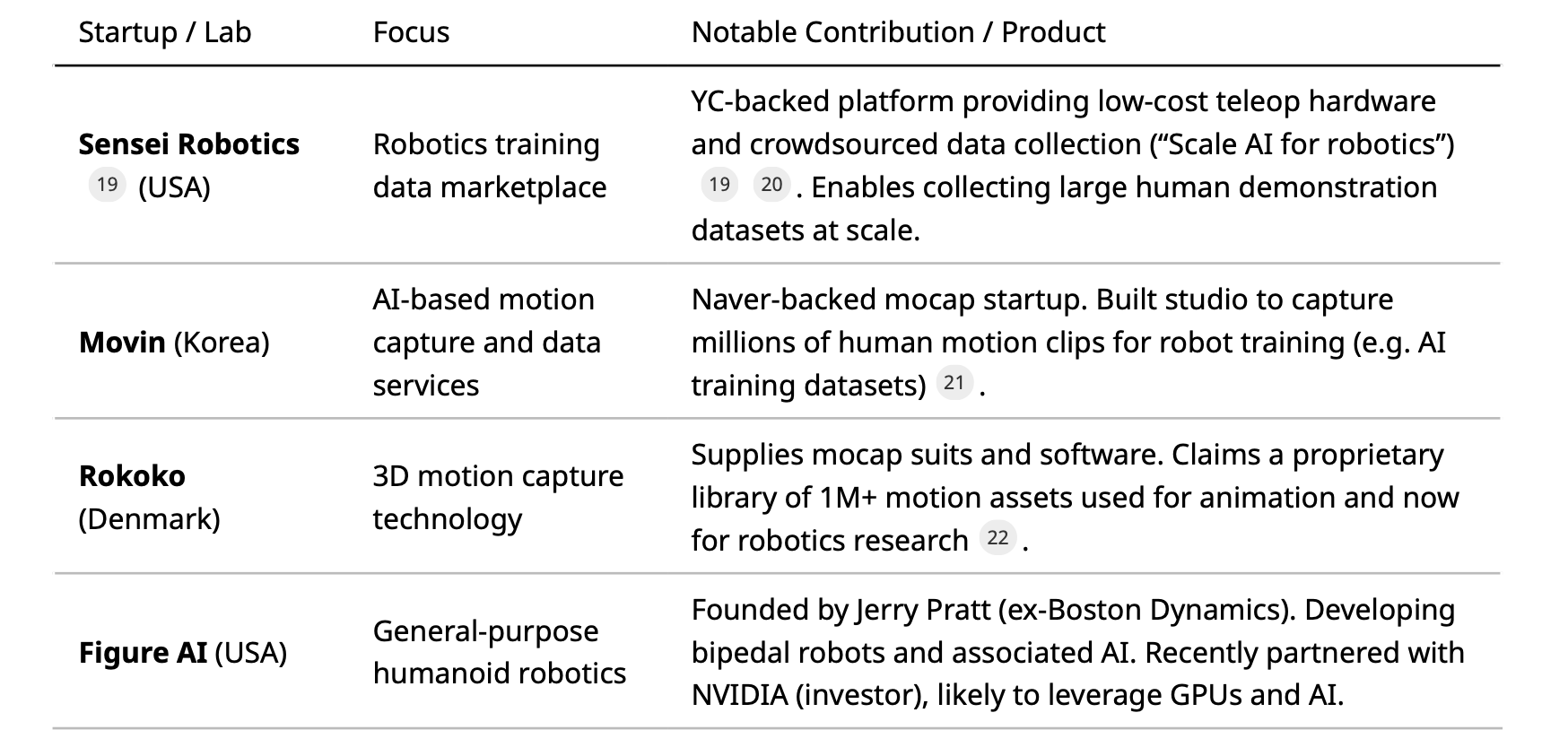
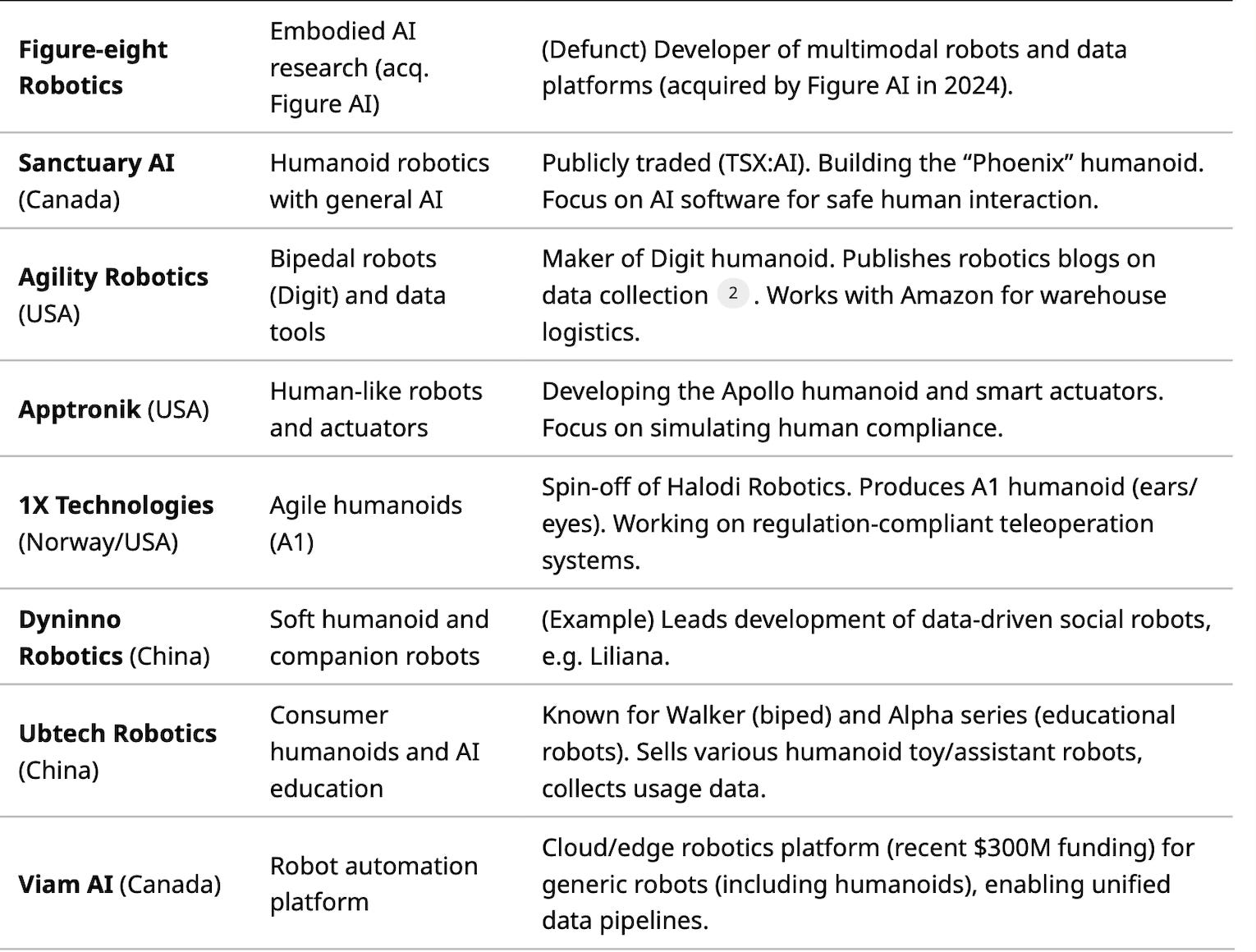
Table 1: Selected startups in humanoid robotics and robotic data technologies. Includes companies building humanoid platforms or enabling data collection (teleop hardware, motion capture, data marketplaces).
These startups often partner with academic labs. For instance, Sensei’s founders have MIT/BAIR backgrounds, and Figure AI’s CTO was on CMU’s Atlas team. Robotics startup accelerators (e.g. Y Combinator) are also funding data-centric companies, reflecting the trend that “data is the new oil” in robotics.
Major Humanoid Robotics Companies
Numerous large corporations are pursuing humanoid robots. Table 2 lists major players, their humanoid projects, and any known data initiatives or publicly shared resources:
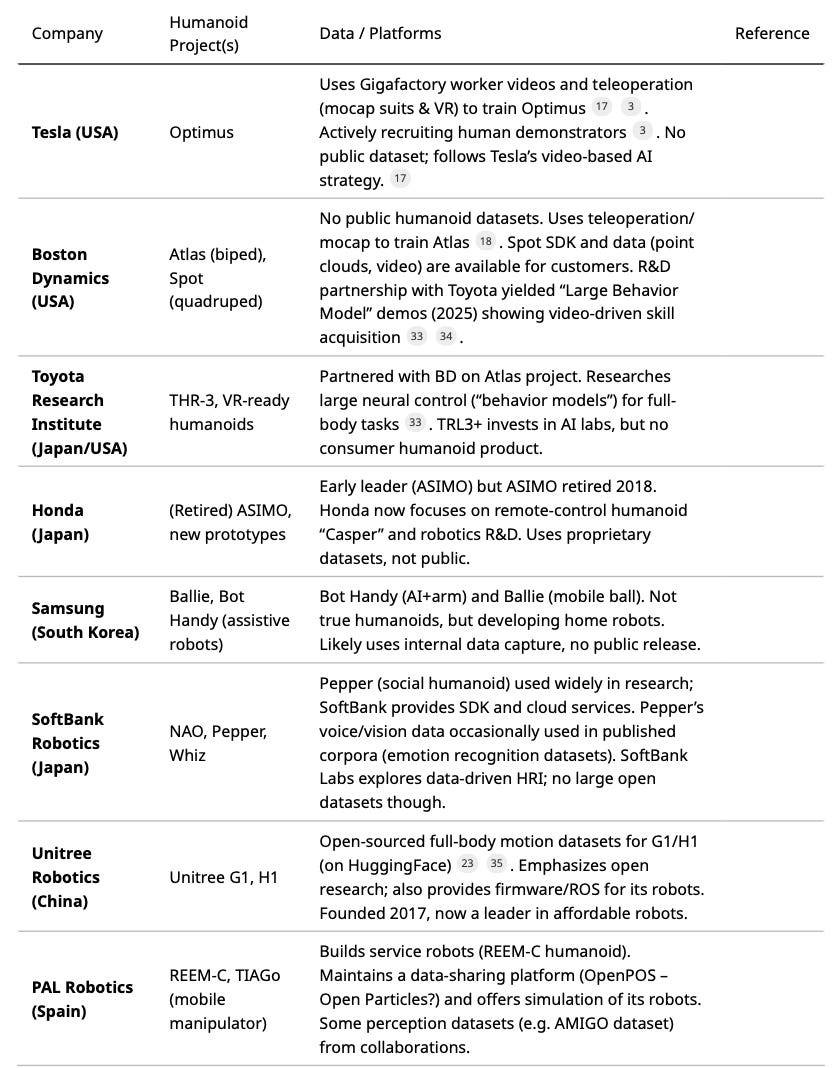
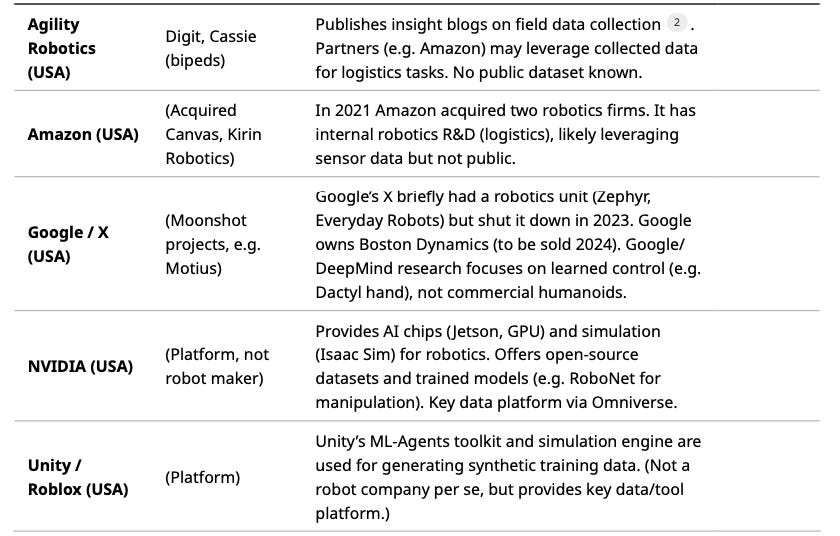
Table 2: Major companies building or supporting humanoid robots, with their projects and data initiatives.
Notably, Tesla and Boston Dynamics are often cited. Tesla’s data strategy shift (to video)[17] and open hiring indicate its heavy focus on data. Unitree’s open-sourcing of motion data[23][35] is an example of a company sharing resources. Overall, most big players keep their data proprietary, but we see a trend toward giving researchers (and sometimes the public) limited access to simulation tools or motion datasets.
Public Datasets and Platforms
While few large-scale humanoid-specific datasets exist, the community leverages related datasets and platforms:
Kitchen and manipulation datasets: The “Kitchen Skills” dataset (Ren et al. 2025)[36] provides ~11 hours of multimodal data (vision, audio, tactile, EMG, body pose) from humans using kitchen tools. This bridges the unimodal data gap in skill learning. Similarly, ActionNet (2022)[37] captures extensive wearable and video data of people performing two-handed tasks in a kitchen. These provide examples of complex daily activities for imitation.
Motion capture corpora: Large human motion databases (CMU, LAFAN, KIT Whole-Body) are repurposed for humanoids. Unitree’s recent release[23] repackages LAFAN1 data for its robots. The human activity dataset EgoMimic (GT/Meta) is available via HuggingFace[4]. The OpenIMINT and NTU RGB+D datasets (action videos, skeletons) are used for initial training.
Robotic simulators and benchmarks: Platforms like AI2-THOR, Habitat, and BulletGym provide simulated environments with varied household tasks. While not humanoid-specific, many researchers test humanoid control (locomotion+manipulation) in these. The [41] Multi-modal Datasets collection (GitHub) catalogs many multi-sensor datasets (e.g. EGAD, ManiSkill).
Company-specific APIs: Some companies release SDKs that include sample data. For example, Boston Dynamics’ Spot SDK includes sample LIDAR and camera logs. Unity’s and NVIDIA’s robotics toolkits include sample scenes and annotated trajectories. These are informal “data sources” for developers.
In summary, comprehensive public datasets are scarce, and much data comes from custom experiments or private corpora. The tables and sources above illustrate the few existing shared datasets (e.g. Unitree’s, academic kitchen data, action datasets) used to train and benchmark humanoid skills.
Key Research Papers and Resources
Table 3 highlights influential academic and industry publications (2019–2025) on humanoid robot perception, data, and learning. Each entry includes a brief summary:
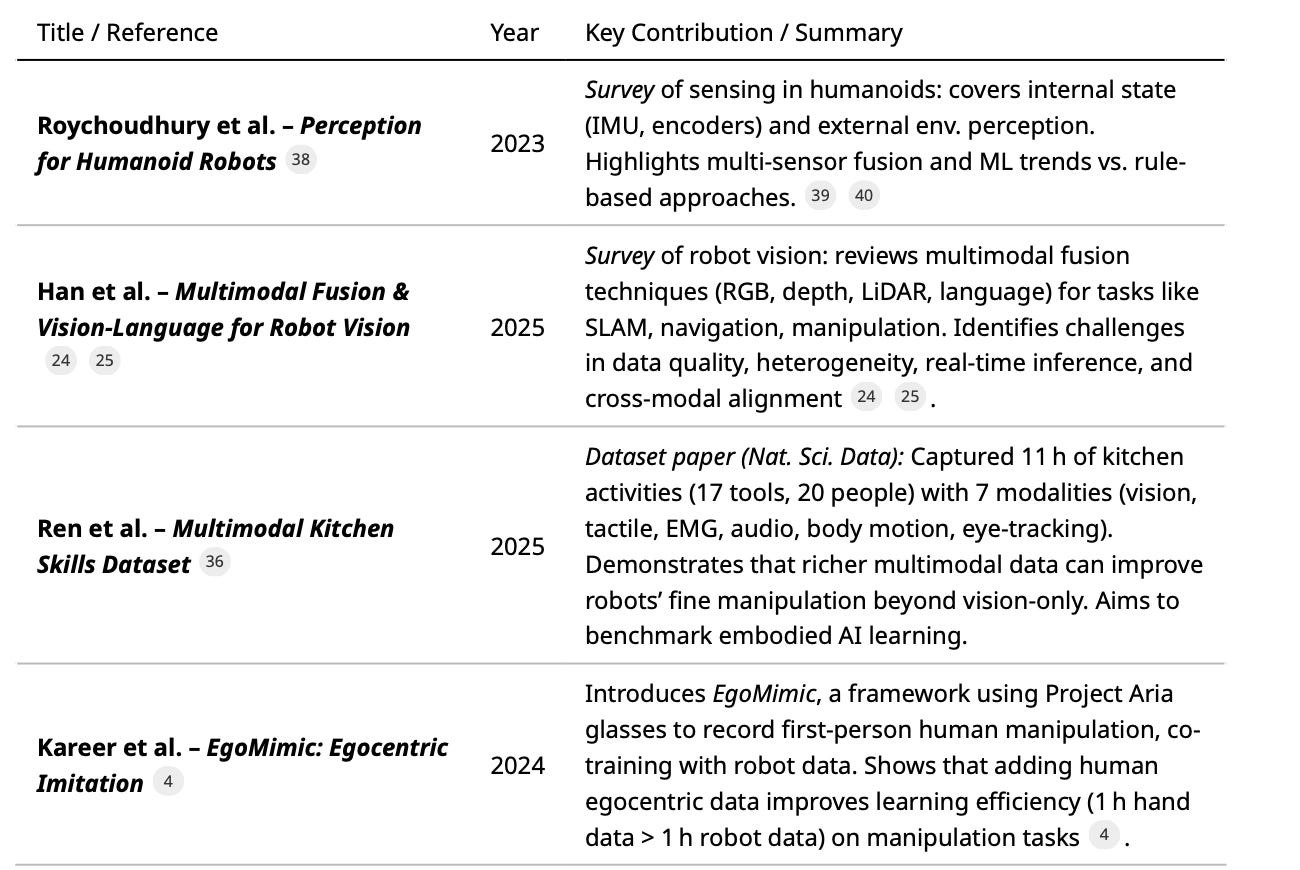
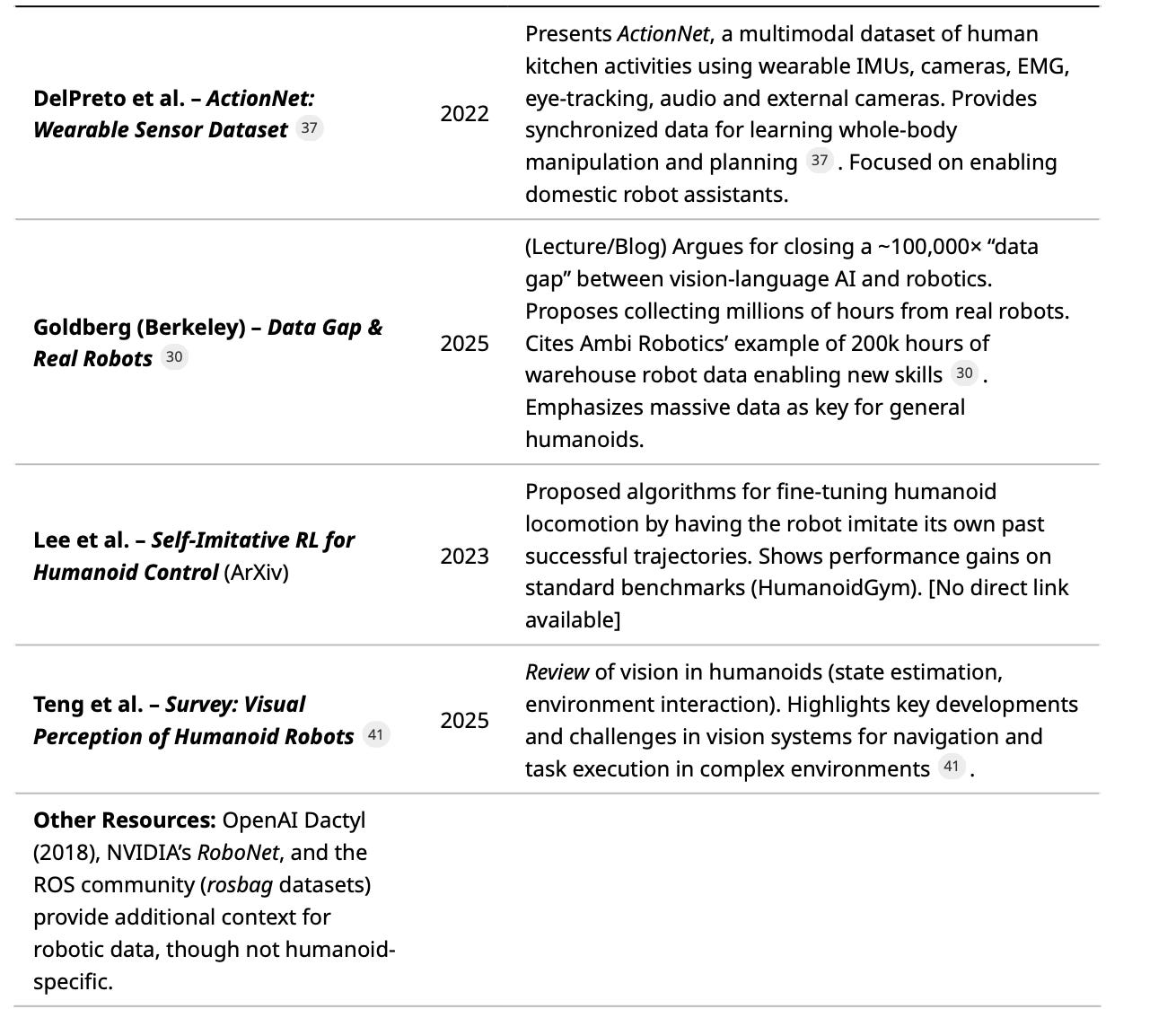
Table 3: Representative papers and reports on multimodal perception, datasets, and learning methods for humanoid robots (2019–2025). Each entry is a peer-reviewed paper or prominent report with key ideas cited.
These papers illustrate the trend toward rich multimodal data and large-scale learning. Survey papers[39][24] emphasize sensor fusion and ML dominance. Dataset papers[36][37] demonstrate that adding modalities (touch, EMG, gaze) can unlock new capabilities. Emerging works like EgoMimic[4] pioneer leveraging everyday videos for robot imitation, hinting at future data-driven paradigm shifts.
Conclusion
Data collection for humanoid robots is evolving rapidly. On the hardware side, robots now pack a “Swiss Army” of sensors (cameras, lidar, IMUs, force sensors, microphones) whose multimodal outputs must be tightly synchronized and fused. On the software side, advances in deep learning and vision-language models are enabling robots to interpret complex scenes and instructions from this data. Recent trends (motion-capture teleoperation, video-based learning, crowdsourced data platforms) are scaling up demonstration data, but a vast gap remains between current datasets and the scale needed for truly general intelligence[30].
Critical challenges include capturing data in real time under bandwidth/compute constraints, generating diverse training data (while preserving privacy), and establishing industry-wide standards for data formats and sharing[30][31]. Startups like Sensei Robotics and Movin are addressing data bottlenecks with new collection platforms, while major players (Tesla, Unitree, Boston Dynamics) explore ways to open-source or better utilize their data[17][23].
In summary, enabling universal humanoid robots hinges on comprehensive data pipelines: from rich sensor suites and AI models, through innovative collection strategies, to collaborative data ecosystems. The literature and products of the past five years reflect a momentum toward multimodal fusion and large-scale learning, but also underscore that “closing the data gap” remains an open frontier[30][24].
Reference:
Authoritative reports, journals, and company publications from 2019–2025, including Agility Robotics[2], Boston Dynamics[1], Sensei (YC)[19], Scientific Data[36], Yale Engineering[30], and industry news[31][17][23].
[1] [5] [6] [7] [8] [9] Robot Vision Systems: 3 Ways Robots See the World | Boston Dynamics
https://bostondynamics.com/blog/3-ways-robots-see-the-world/
[2] [12] [14] [15] EXPLAINED: Data Collection & Humanoid Robots
https://www.agilityrobotics.com/content/explained-data-collection-humanoid-robots
[3] Tesla recruits data collection operators for Optimus bot
https://www.teslarati.com/tesla-optimus-data-collection-operator-job/
[4] EgoMimic : Scaling Imitation Learning via Egocentric Video
https://egomimic.github.io/
[10] [11] [38] [39] [40] Perception for Humanoid Robots | Current Robotics Reports
https://link.springer.com/article/10.1007/s43154-023-00107-x
[13] [29] [36] Enhancing robotic skill acquisition with multimodal sensory data: A novel dataset for kitchen tasks | Scientific Data
[17] [18] Inside the Strategy Shift at Optimus, Tesla's Humanoid Robot Program - Business Insider
[19] [20] Sensei: Robotic Training Data at Scale | Y Combinator
[21] Naver-Backed Motion Capture Startup Movin Expands Into AI ...
[22] Unlocking Motion Data for Humanoid Robotics with Rokoko
https://www.rokoko.com/insights/unlocking-the-data-infrastructure-for-humanoid-robotics
[23] [35] Unitree's humanoid robots dance like humans with open-source data set
https://interestingengineering.com/innovation/unitree-humanoid-robots-dance-data-set
[24] [25] [26] [27] [28] Multimodal Fusion and Vision-Language Models: A Survey for Robot Vision
[30] Igniting the Real Robot Revolution Requires Closing the “Data Gap” :: Yale Engineering
[31] [32] China Wants More Data-Sharing for Humanoid Robots - Rockingrobots
https://www.rockingrobots.com/china-wants-more-data-sharing-for-humanoid-robots/
[33] [34] Video: Atlas Shows Large Behavior Model - Rockingrobots
[41] A survey on the visual perception of humanoid robot – DOAJ